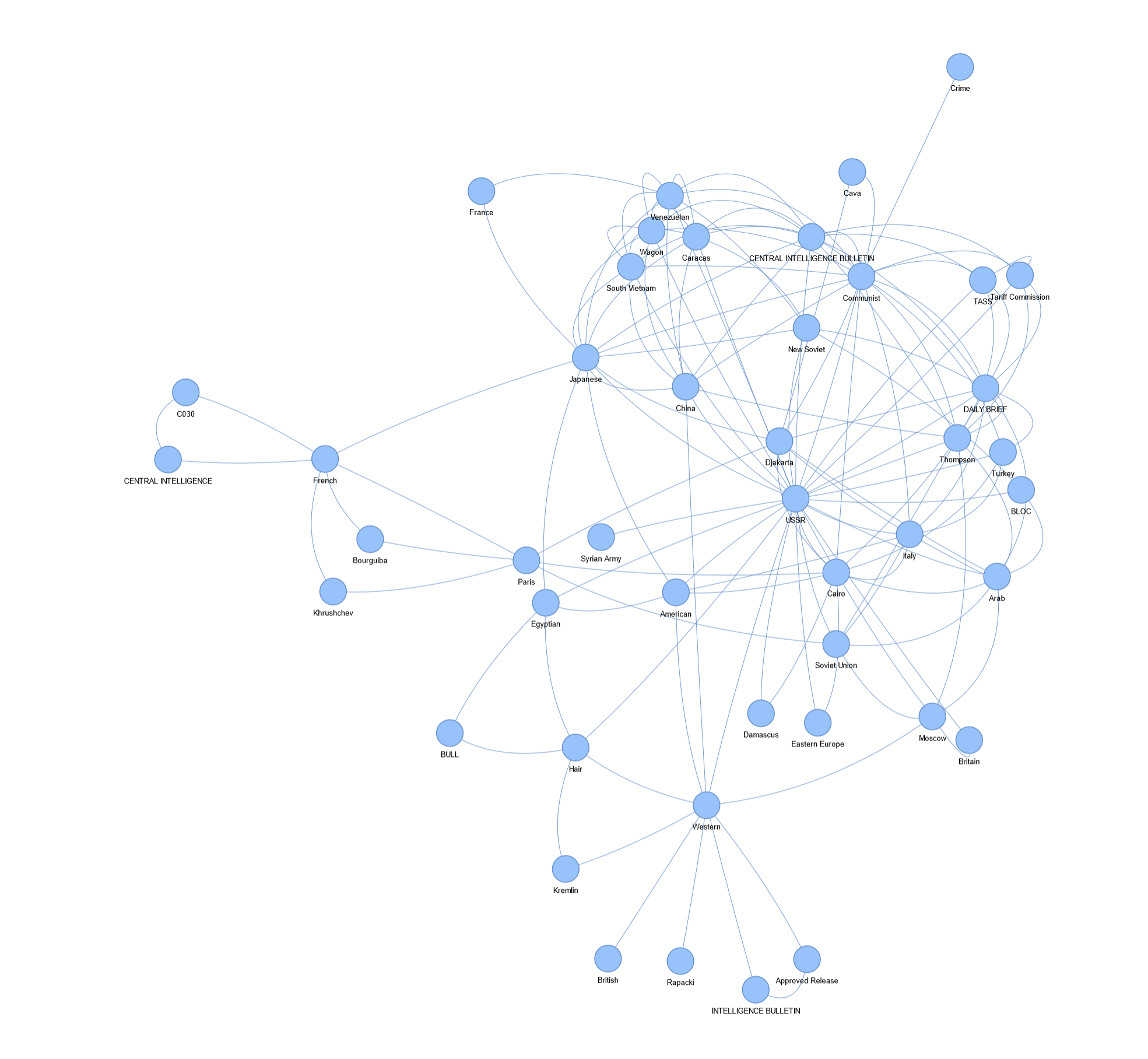
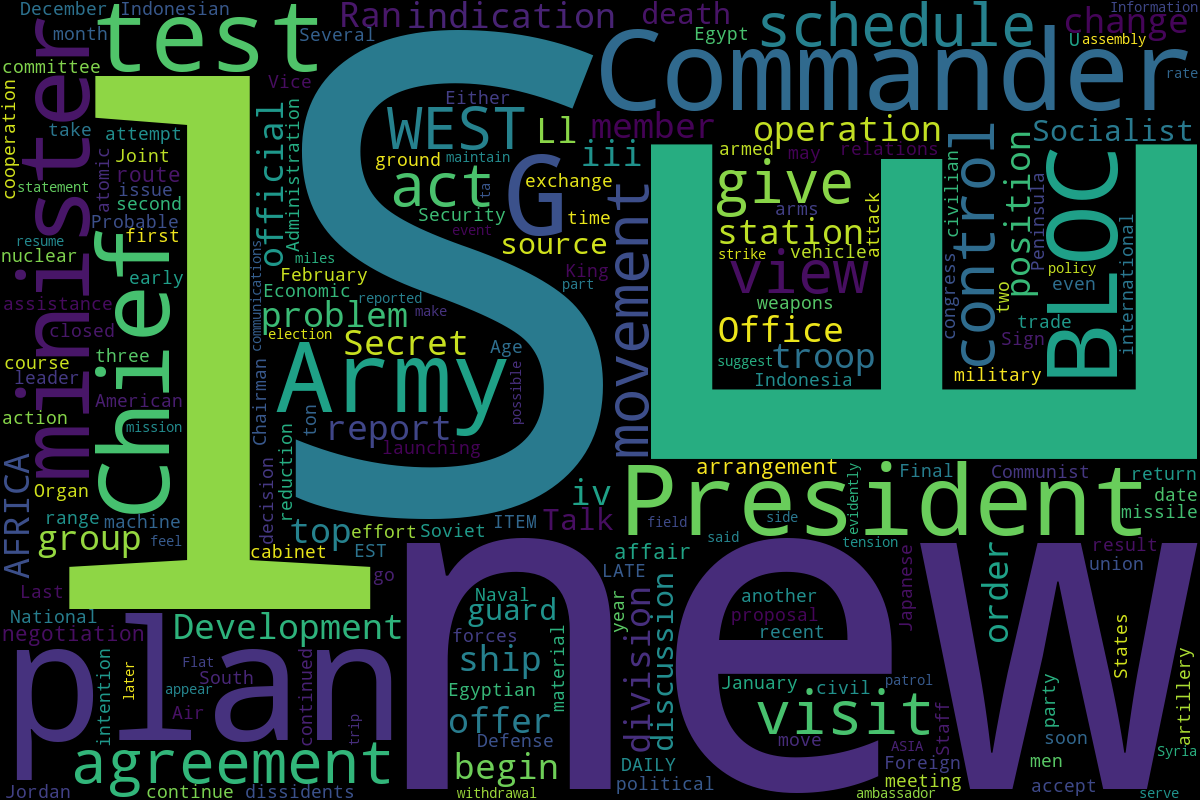
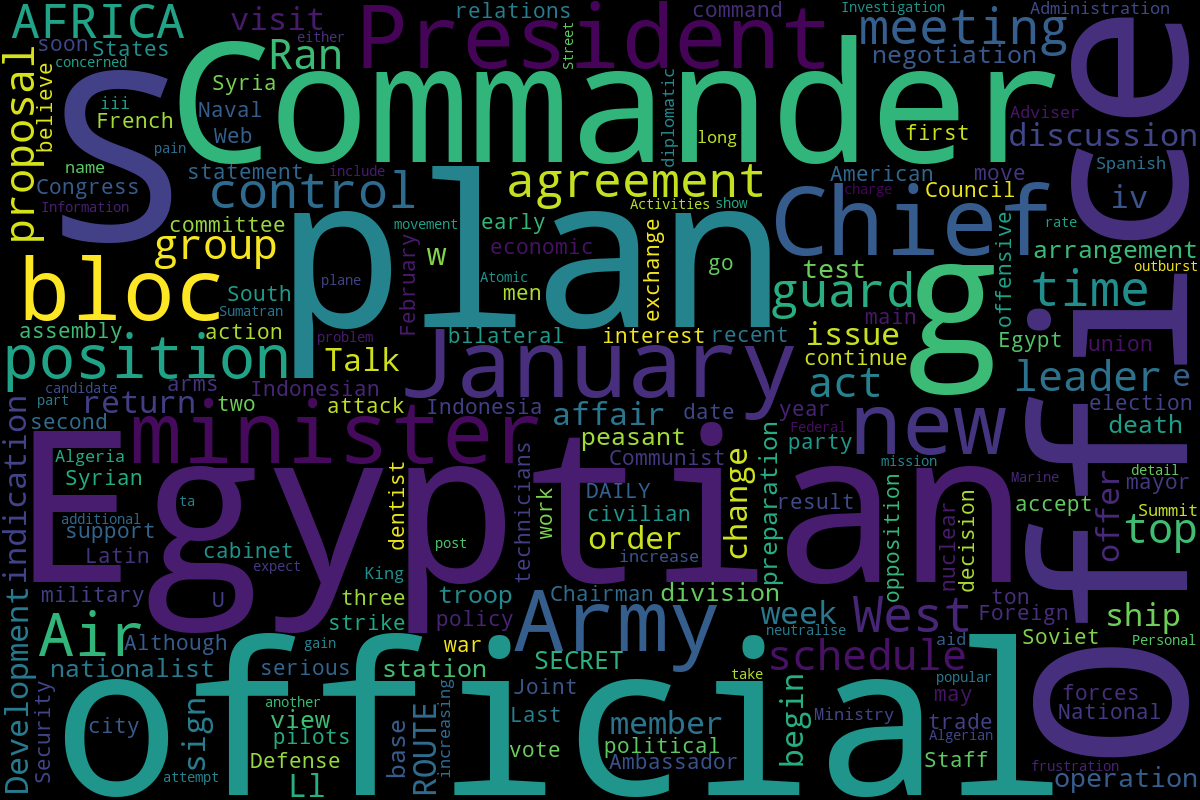
In this project, I scraped 2809 declassified CIA briefings to the president from the 1950s and examined the data using a variety of Natural Language Processing (NLP) techniques.
I chose this dataset because it seemed perfect for experimenting with NLP -- reading all of these briefs and identifying patterns would be immensely time-consuming, and it would be easy to miss larger themes. THis is where NLP can be useful.
First, I used the Python module BeautifulSoup (though in hindsight, I really regret not looking into Scrapy) to scrape the CIA website, which does not prohibit web-scraping.
Once I had the data, which were scans in PDF format, I transferred it to plaintext and did a bit of pre-processing before exploring it.
Pre-processing included removing random noise from the original document (smudges from photocopies and stamps showed up as gibberish and random punctuations when transferred to plaintext), removing common words with little meaning (stop words), spellchecking and lemmatizing the rest of the words (putting words in their root form).
Spellchecking was the most computationally expensive step in this process. Because the documents were photoscans from the 1950s, a lot of words transferred to text incorrectly. For example, the word 'example' may have been coded as '3x ample' or 'exmq1e'.
To get around this, I created a function that checked the word similarity of every word to known words using the Python modules Gensim and Textblob. If there was a match of over 90%, the correctly spelled word was used. Otherwise, the word was abandoned.



{kind=link}